You're in IT, right? So chances are you've been laid off at least once from some crappy company and it's going to happen again. Here is my one piece of advice to you. The single most important thing to do as soon as you make it back to your house with that box full of stuff:
Book a flight
Seriously. Do it now, before the initial shock wears off and that logical side of your brain starts coming up with lame excuses. You will never have a better chance to get out and see the world than right now. You have a pile of saving and a severance package. You've got 6 months to a year before your skills start getting rusty. There is absolutely no reason to start looking for work immediately, and every reason to take that round-the-world trip you've always dreamed about. Right. Now.
Trust me, your career will be just fine.
Where to go
This is the easiest question to answer:
Bangkok. Seriously, the mere fact that you had to ask the question indicates that you're probably not a seasoned traveler and therefore should be going to Thailand first. I know you always wanted to do Europe, but it's crazy expensive and frankly, it's just not relaxed enough for you right now. You're going to need some serious chilling to recover from a layoff. Southeast Asia has that in Spades.
Make your way to Khao San Road, find a room, grab a Beer Chang and talk to a few other travelers. Your trip will plan itself from there.
Where to go if it's May
Ok, one modification to the above. Thailand is thoroughly uninhabitable for a few months between May and July. In that case, you're going to Africa. Book a flight to Cape Town instead. Follow this itinerary up through Zambia, Malawi and Tanzania. Everybody there speaks English and you can get a room for $0.75. You'll do fine.
How long to go for
You're going to want to stay gone for 6-9 months. Less than that and it you'll be kicking yourself for not leaving enough time, and you'll be rushing through entire countries just to keep up with your itinerary. I know that this seems silly now, but somewhere along the way somebody will ask how long you've been in Vietnam for and you'll answer "Only one month." Timescales work differently on the road.
In my experience (did I mention that I take about 9 months vacation a year and spend most of that traveling in the developing world?), I tend to start missing work after about 6 months away. By 9 months, I'm pretty much ready to commit to a real job in a real office just so that I can start using my brain again. Talking to other software guys on the road, it seems that this is pretty common. You're going to want to come back eventually, so be sure to keep a few good contacts back home.
Regardless of how long you plan to be gone, try to book your flight one-way. It will give you unlimited flexibility with your travel plans and let you pick your return date later when you know what you actually want to do. As a last resort, pick the return date furthest in the future, since it's a lot easier to move it forward than to push it back.
How much will it cost?
I budget about $1,000 a month when I'm traveling in Southeast Asia, Central America, Africa or the Middle East. I seldom go through that much if I'm sticking to ground transport, but over the course of a year if you consider flights into the calculations, $1,000 a month is about right. Stay away from the developed world at all costs though, or you'll quickly triple that figure!
How do I get another job when I get back?
The nice thing about a 6 month timeframe is that it gives all of your ex-coworkers time to entrench themselves in other hopeless software companies. Email them and notice how everything around them seems to be on fire. They need you to start tomorrow. Line up a good offer based on one of their recommendations and book a flight home.
Three Lame Excuses and why they're not valid:
But I don't have any money saved...
You can't possibly be serious. Are you saying that you've been working in IT for all these years and haven't put away a lousy ten grand??? Shame on you. Get a book on life skills and open a bank account fer cryin' out loud.
But nobody will hire me after six months away...
Not true. Nobody will hire you if you're bad at what you do and have terrible interviewing skills. Those things won't change over the course of six months, but you might possibly wind up more relaxed (and with some good stories to tell) and that's actually a benefit when it comes to interviewing.
Regardless of what you may have heard, skilled developers are very hard to find. If you fit that category, there's very little that you can do to poison your resume. Certainly, heading off on your once-in-a-lifetime trip won't leave you unemployable.
But I'm married with a family and a house...
Ok, you win. You're screwed, but that's the life you chose for yourself so you're going to have to live it. It's worth noting, however, that most Europeans wouldn't consider that a reason not to travel. Right this second, there is a German couple pushing a stroller down a remote beach in Thailand, and they're not going home for another month. What's your excuse again?
Why you're not actually going to do it
When you get right down to it, you'll probably find a way to talk yourself out of taking that dream trip. You'll come up with some pretty believable excuses, but really it will come down to the fact that you're scared.
That's cool. Travel is pretty scary when you look at it from the outside. But here's the thing. It stops being scary the moment your feet hit the pavement on Khao San Road in Bangkok. You're going to get blasted by 100 degree heat, power-wafted by smells of the most amazing street food one minute and an open sewer the next, assaulted with music from a thousand bars, and crammed into a tiny room overlooking it all with a fan that doesn't work. And you won't be able to wipe the silly grin off your face.
Book the flight today, because every day you delay it is one more day wasted on the couch, and one more day to come up with lame excuses for why you shouldn't go.
It is all good here. Get your ass on a plane.
by
Jason Kester
 Discuss on hacker news
Discuss on hacker news
PHP used to have a cool little feature where it would automatically detect single quotes in text strings and escape them for you whenever they needed to be. It was called Magic_quotes_runtime. Maybe you've heard of it.
It was a disaster.
Countless developer hours were spent trying to chase down mysterious runtime errors where single quotes were either introduced, doubled up, or removed, causing disastrous crashes, data corruption and so much untold havoc that the feature was deprecated and eventually
removed from PHP entirely.
You would think that people would have learned their lesson.
People are, by and large, dumb. We make the same dumb mistakes over and over again because we didn't bother to do any research or read about the last time that somebody tried whatever stupid idea we just re-invented. As a result, we have development frameworks and tools like
Hibernate, ASP.NET's
SmartNav, and Rails'
ActiveRecord, all trying to magically solve problems that weren't very hard in the first place, and silently making a lot of people's lives a lot harder without them even realizing it.
The big problem with Magic tools is that they work fine the first time you try them. "Wow!", you say, " It posted the page back and scrolled my browser back down to the Submit button!" So you turn that feature on for all your pages and start to trust it. You get used to it. You take it for granted. You forget you're even using it. Then suddenly something weird starts happening with one of your pages and you can't figure out why.
Examples of this sort of side effect abound, but nobody yet has taken a stand and done something about it. How many developer hours have been lost trying to figure out what magical SQL statement was running behind the scenes and only “Hibernating” half of an object? How many CPU cycles have been squandered (and slanderous blog entries written) because some poor developer didn’t realize that ActiveRecord was hitting the database three times for every single row in that recordset? Are we really so scared of Outer Joins that we allow ourselves to be subject to this torment?
I’ll leave you with an axiom that I’ve been telling developers for years without much success. Call it Kester’s Caution:
Never use any language feature that describes itself as "Smart" or "Magic."
Such features will invariably be trying to abstract
out some behavior that is not that hard to deal with anyway, and will
make any number of incorrect assumptions about your application that
will result in strange behavior cropping up that could possibly be
described as "Magic", but certainly would never be labeled "Smart".
by
Jason Kester
Discuss on hacker news
 Twiddla
Twiddla has been getting a ton of attention this week. We picked up the
Technical Achievement award at SXSW Interactive, and have been getting a bunch of good press ever since. 25,000 people have signed up for the service since the award was mentioned, with 7,500 of those signups happening in a single day. It's about to get good.
For me though, it's been even better. We're finally getting enough traffic to start thinking about scaling issues. You might remember an article that I wrote a few months back, where I told people
not to sweat Performance and Scaling issues too much, but rather to focus on Readability, Debugability, Maintainability, and Development Pace. The idea was that getting your product to market quickly and being able to move fast if necessary are more important than having the Perfect Dream System that takes forever to build. Of course, the implied point was that when and if that Big Day came, you'd be able to move fast enough to deal with Scalability and Performance concerns as they appeared.
On March 12th, 2008, I got to see first hand whether I was talking out my arse…
3/11/2008 7:00pm: 150 signups/hr, 50 hits/sec, 0-5% CPU
It's the day after the awards, and the first brief announcements are out. Traffic has been building steadily all day, but we've seen worse. The only crisis at the moment is that we don't yet have a
Press Kit, so we're seeing writeups with the old logo and screenshots from the old UI. D'oh!
3/11/2008 11:00pm: 350 signups/hr, 120 hits/sec, 1-9% CPU
Japan wakes up. The Asian press really liked us, so we saw a big spike in users from China and Japan the first few days.
The sandbox is pretty clogged, and with 30 people drawing simultaneously it's starting to tax people's browsers. Every once in a while, somebody navigates the sandbox over to a porn site, and people write our support line to complain. We're wiping the sandbox every 5 minutes, but it's still not acceptable. Gotta get a handle on that.

3/12/2008 9:00am: 300 signups/hr, 100 hits/sec, 1-6% CPU
The sandbox is completely overloaded. There are 100 people in there, which is too many people communicating at once for any medium to really handle. Imagine 100 people drawing on a real whiteboard at the same time, or 100 people talking over each other on a conference call. It just doesn't work. To bring a little order into the picture, I fire up the Visual Studio.NET and add a little switcher that will direct traffic to any one of 5 sandboxes, each one holding 8 users. Throw that live, and now there are 5 overloaded sandboxes.
3/12/2008 9:30am: 500 signups/hr, 300 hits/sec, 3-15% CPU
I bump up the sandbox count to 10. Then think better of it and bump it up to 20 before pushing. Then think better of THAT and add a new page to show users in case all 20 of those sandboxes fill up. Push that live.
3/12/2008 9:41am
Testing out the above changes, I am immediately redirected to a page saying "Sorry, all the Sandboxes are full." Let me restate that: From the time I pushed those changes live to the time I could test them out, 160 people had beaten me into the sandboxes. Wow.
3/12/2008 10:00am: 700 signups/hr, 500 hits/sec, 5-20% CPU
Looking through the error logs, I'm starting to see our first concurrency issues. These are the little one-in-a-million things that you'd never find in test, but that happen every ten minutes under load. They're mostly low-hanging fruit, so I spend the next hour patching and re-deploying until the error logs go silent.
3/12/2008 12:00pm: 600 signups/hr, 400 hits/sec, 5-17% CPU
I'd been doing all of this from my sister's house up in Ft. Worth, who I had supposedly been visiting for a couple days, but whose house I had been mostly using for an office (thanks Lisa for tolerating that, and I promise to get out and visit sometime when I'm not trying to launch a new website!) Now I had to hop in the car and drive back to Austin to fly home. Our trusty server will be on its own for the next 12 hours, taking the beating of its life. I won't even know if it goes down.
3/13/2008 4000 signups/day, 100 hits/sec, 3-10% CPU

Twiddla ArtBack in a stable place, and ready to deal with the flood of feedback emails we've been getting. This part is fun, since most people have nice things to say, and it becomes readily apparent what features everybody wants to see. Nothing has broken, so I actually have some time to put a few minor features live. The "Wite-out" button was added this day, I think, and I re-did the way we handle snapshots and image exporting.
3/14/2008 3000 signups/day, 100 hits/sec, 2-5% CPU
I implemented a fix for the last little concurrency bug that we'd been seeing. Then, while profiling that fix on the server, I noticed that TwiddleBot was flipping out. TwiddleBot is the little service that runs the Guided Tour feature, and is also responsible for clearing out the sandboxes from time to time. Turns out, he was also pounding the database 20 times a second, asking for instructions. Hmm… Chill, TwiddleBot. Pushed a fix for that, and suddenly CPU usage dropped to zero. Like, ZERO! Every 5 seconds, it would spike up to 1%. Cool. I think we're gonna be able to scale this thing…
One week later, ~1000 signups per day, 50 hits/sec, 0% CPU
In the end, we came through our first little scaling event rather well. We were actually a bit over-prepared. Our colocation facility (
Easystreet in Beaverton, Oregon) had a couple extra boxes waiting to go for us, and I had taken the time a week earlier to write up and test a little software load balancer to allocate whiteboard sessions to various boxes when needed. In the end, we didn't get to try any of that out. Hell, we never spiked the processor on our one server over 50%. I'd love to congratulate myself for the design choices I made all those months back when I wrote that article, but I think it's still too early in the game to conclude that we'll really scale when we ramp up to the next level.
Still, it's worth noting that everything in Twiddla was built using the simple, Readable, Debuggable backend that we've been using on our more pedestrian sites for years, and it held up just fine under traffic. When it turned out that parts of that backend needed refactoring to handle the kind of concurrency we saw last week, it was a simple 5 minute task to crack open the code, find what needed to change, and change it.
Readable, Debuggable, Maintainable. That's the plan. Thus far, that has enabled us to keep on top of any Performance and Scalability issues that have come along. With luck, things will continue to work that way!
by
Jason Kester
Discuss on hacker news
Everybody in the world is talking about the
Big Amazon Outage yesterday. It hit us pretty hard. A few of our sites were serving broken image links for several hours yesterday, and a service we run that relies on SQS was completely dead in the water.
You know what though? It's just not that big a deal. I think about how reliable my stuff was before I put it up on Amazon's machines, and really it wasn't any better. The only difference here is that I couldn't jump onto the server and do the hotfixing myself. I didn't get to spend all day writing a patch to some low-level shared thing that suddenly started misbehaving system wide.
Hey, wait a minute. Scratch that.
I didn't HAVE to do anything at all. It was somebody else getting that page at 3AM and scrambling to get my site back up. This is actually better from my perspective.
So yeah, my sites still see the rare hour-long down window. But now it's not my problem anymore.
Cool.
by
Jason Kester
Discuss on hacker news
You can safely ignore this post. I'm using it as a shortcut to get this page about
vistacular margarine indexed as quickly as possible.
If you're interested in what I'm up to, view source on that page. It's a test to see if it's feasible to publish content as simple XML documents that look like HTML, and do all the site navigation and chrome using client-side XSLT.
At this point, I doubt it's going to work, but we'll see...
by
Jason Kester
Discuss on hacker news
Amazon's Jeff Barr was kind enough to do a writeup of
S3stat on the
Amazon Web Services blog. Thanks for that!
I doubt that S3stat will ever bring in enough income to pay the rent, but it's nice to see that people are getting some use out of the thing. At the end of the day, that's sorta why we build software in the first place, right?
by
Jason Kester
Discuss on hacker news
Human-powered comment spam has been piling up recently at
Blogabond, so I spent a few hours putting together a C# implementation of
Paul Graham's Naive Bayesian Spam Filter algorithm.
You can find a nice long-winded article along with the source code over at
The Code Project. Let me know if you find it useful. Here's a link:
https://www.codeproject.com/KB/recipes/BayesianCS.aspx
by
Jason Kester
Discuss on hacker news
WARNING: This Article is Out Of Date
I wrote this a year ago and, checking now, the link below is broken. Sorry about that!
If you do find a good site that's working this year, please let me know at
[email protected] and I'll update this article.
The Superbowl may be the most important event in the American sports calendar, but most of the world just doesn't care about it. So what do you do if you're out of the country when it happens?
I grew up in the Pacific Northwest, a place where it generally sucks to be most of the winter. As soon as I could do anything about it, I made a point of getting away for at least a month or so every winter. That did great things for my suntan, but I always seemed to be out of the country for the Superbowl.
In most parts of the developing world, that wasn't such a big deal. In Honduras, I watched the game in a beach bar over marlin steaks and beers. In Malaysia, it was just a matter of banging on the door of the local "english pub", waking up the barman, and finding the game on TV. On the beach in Thailand, all it took was a 6am raid to kick on the generator at one of the beach bars, thus waking up the staff and asking for a large pot of coffee while I figured out how to work the TV.
Europe, however, is a different matter. Try convincing the surly Basque behind the counter to keep his bar open until 2am on a Sunday, and you'll see what I mean. If you can find a hotel room with a TV, maybe you'll be in good shape, but only if they happen to have a good satellite provider that happens to carry the game.
So here I am, with 11 hours to spare, furiously scouring the web, looking to find a way to stream the game to my laptop. If you're reading this article on Superbowl Sunday, chances are you're doing the same thing. Here's the story:
The big players in streaming video don't seem to be much help.
Yahoo's NFL Game Pass doesn't do postseason games.
The NFL doesn't seem too interested in streaming their games, even after
a petition from football fans asking for it.
DirectTV will actually let you watch the Superbowl live! You just need to sign up for their $269 football season pass and then give them another $99 for their "SuperFan" program that gives you access to the Big Game. Uh... Thanks?
Cricket to the rescue!
What to do then? This obscure British website called
Cricket on TV will give you a pass to watch the Superbowl for $15. It's that easy. Just sign up at their site, give them your credit card details, and go start stocking up on beer & pretzels. Sorted.
Again, for those just scanning down:
This site had last year's Superbowl on Streaming Video, but it's gone now.
Too bad you can't get it for free. But hey, if you're a football fan, you know that this is important. It's worth the money.
by
Jason Kester
Discuss on hacker news
Edit:

Web Stats for Amazon S3
This was written before we launched
S3stat, a service that parses your Amazon S3 server access logs and delivers usage reports back to your S3 bucket.
So if you're not interested in the technical details, and just want web stats for your S3 account, you can head over to
www.S3stat.com and save yourself a bunch of hassle.
Amazon's
Simple Storage Service (S3) is a great content delivery network for those of us with modest needs. It's got all the buzzwords you could possibly want: geo-targeted delivery, fully redundant storage, guaranteed 99.9% uptime, and a bunch of other stuff that you could never pull off on your own. And it's dirt cheap.
Of course, there's always a catch, and in S3's case you'll soon find that your $4.83 a month doesn't buy you much in the way of reports. With some digging around at Amazon's AWS site, you can find out how much you were charged last month, but that's about it. (OK, If you're persistent, you can download a CSV report full of tiny fractions of pennies that, when added together, tell you how much you were charged last month.)
The Motivation
I love my web statistics. I'm up and waiting at 12:07am every morning for the nightly Webalizer job to run so that I can see how many unique visitors came in to
Blogabond today (1227), and what they were searching for (
tourist trap in Beijing). I've been hosting my user's photos out at S3 for a few months now, and though I've watched my bandwidth usage drop through the floor, I've also been missing my web stats fix for all those precious pageviews. Something had to be done. I started digging around through Amazon's AWS docs.
It turns out that you can actually get detailed usage logs out of S3, and if you're willing to suffer through some tedium, you can even get useful reports out of them.
Setting it up
Turning on Server Access Logging is just about the easiest thing that you can do in S3. If you've ever tried to use Amazon's APIs, you can translate that to mean that it's hard. It takes two steps, and unless you're looking at a Unix command prompt, you'll need to write some custom code to pull it off. Here's what you do:
1. Set the proper permissions for the bucket you'd like to log. You'll need to add a special Logging user to the Access Control List for the bucket, and give that user permission to upload and modify files.
2. Send the "Start Logging" command, including a little XML packet filled with settings for your bucket.
The nice people at Amazon have put together a
simple 4 page walkthrough that you can follow to accomplish the above. I've run through it, and it works as advertised
Parsing the logs
Now we're getting to the fun part. Remember above where we noted that S3 has servers living all over the world delivering redundant copies of your content to users in different countries? Well now we get to pay the price for that. You see, Amazon sort of punted on the issue of how to put all those server logs back together into something you can use. Instead, every once in a while, each server will hand you back a little log fragment containing anywhere between 1 and 1,000,000 lines of data. Over a 24 hour period, you can expect to accumulate about 200 files, ordered roughly by date but overlapping substantially with one another.
So, now in order to get a single day's logs into a usable form, we get to:
3. Download the day's logs. This is simple enough, as the S3 Rest API gives us a nice ListBucket() method that accepts a file filter. We can ask for, say all files that match the pattern "log/access_log-2007-10-25-*", and download each file individually. We'll end up with a folder containing something like this:
10/30/2007 02:13 PM 21,380 access_log-2007-10-25-10-22-37-2C695527C7FEAEE5
10/30/2007 02:13 PM 19,653 access_log-2007-10-25-10-22-37-8FFF80109E278103
10/30/2007 02:13 PM 15,829 access_log-2007-10-25-10-23-24-D97886677E5A8670
10/30/2007 02:13 PM 185,195 access_log-2007-10-25-10-24-11-7F5172BFA139167D
10/30/2007 02:13 PM 94,795 access_log-2007-10-25-10-27-14-3EDC4E89A03E96EB
10/30/2007 02:13 PM 3,812 access_log-2007-10-25-10-32-20-DD96FC8F8B880232
10/30/2007 02:13 PM 121,863 access_log-2007-10-25-10-33-59-A44E699EE741CEF7
10/30/2007 02:13 PM 51,315 access_log-2007-10-25-10-39-52-313F98B8F52AA150
10/30/2007 02:13 PM 34,984 access_log-2007-10-25-11-18-37-DE9AB5D324881BC2
10/30/2007 02:13 PM 8,451 access_log-2007-10-25-11-22-16-BC5BCE4A49C4EC44
10/30/2007 02:13 PM 10,271 access_log-2007-10-25-11-22-54-54F77DE85AD20F84
10/30/2007 02:13 PM 14,949 access_log-2007-10-25-11-23-28-08D3DED923404EA5
4. Transform columns from S3's
Server Access Log Format into the more useful
Combined Logfile Format. In the Unix world, we could easily pull this off with sed. In this case though, we might actually want to process each line by hand, since we still need to...
5. Concatenate and Sort records into a single file. There are lots of ways to accomplish this, and they're all a bit painful and slow. When I did this myself, I wrote a little combined transformer/sorter that spun through all the files at once and accomplished steps 4 and 5 in a single pass. Still, there's lots of room here for speed tweaking, so I'll leave this one as an exercise for the reader.
6. Feed the output from Step 5 into your favorite Web Log Analyzer. This is the big payoff, since you'll soon be looking at some tasty HTML files full of charts and graphs. I prefer the output produced by
The Webalizer, but there are plenty of free and cheap options out there for this.
Wrapping up
And that's about it. Now all that's left is to tape it all together into a single script and set it to run as a nightly job. Keep in mind that S3 dates its files using Greenwich Mean Time, so, depending where you live, you might have to wait a few extra hours past midnight before you can process your logs.
All together, this took me a little more than a day of effort to get a good script running. It wasn't easy, but then nothing about administering S3 ever is.
Epilogue (the birth of S3STAT.com)
I went through this pain and wrote this article about a week ago. Before posting it, it occurred to me that hardly anybody will ever actually follow the steps that I outlined above. It's just too much work, with too little payoff.
What the world needs is a simple service that people can use to just automate the process. Type in your access keys and bucket name, and it will just set everything up for you.
Let's see... People need this thing... I've already built it... ...umm... Hey! I've got an idea!
So yeah, get yourself over to
www.s3stat.com and sign up for an account. It's a service that does everything I described above, and gives you pretty charts and graphs of your S3 usage without any setup hassle. At some point I'm going to start charging a buck a month to cover the bandwidth of moving all those log files around, but for now I just want to get some feedback as to how it's working.
Let me know what you think!
by
Jason Kester
Discuss on hacker news
If you've come within 30 feet of the internet this last month, you'll have come across
this list of best practices at least a dozen times. Everybody seems to be writing about it and linking to it and
building little tools that tell you you're not doing it right.
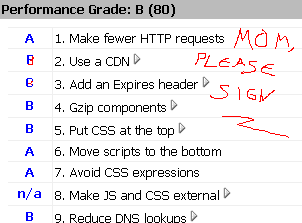
Most of the stuff on that list is low hanging fruit. You can spend 5 minutes in IIS, flipping compression on and telling all your /images/ directories not to expire content until we're all driving flying cars, and suddenly you'll find your site loading a lot faster.
That's cool and all, but what if you also followed their advice and stuck a bunch of your static content out on Amazon S3? I guess you just fire up
S3Fox and start playing with the metadata on all those… whoa, hang on… hey, you can't change that stuff once it's written. Crap. You've gotta upload all those files again. And you can't use that cool Firefox tool to do it anymore, because it has no way to set an "Expires" header when you upload a file. Crap. Crap. Crap.
Well if you're running C# and ASP.NET, you're in luck. Because I just went through that pain for
a few of my sites, and now I'm going to let you mooch off my code.
First step: download the right library from Amazon
In this case, you're going to need the
Amazon S3 REST Library for C#. No, not the SOAP library, because evidently
that one is crap. Either drop the source straight into your project or build it elsewhere and link it in.
Last step: swipe this code
This zip contains everything you'll need. Just airlift it into your project and you'll be good to go. Now, since this is an article about programming, I'm legally obligated to provide at least one code sample for you to gloss over. So here is the meat of what we're doing:
public void PushToAmazonS3ViaREST(string bucket, string relativePath, HttpServerUtility server)
{
relativePath = relativePath.TrimStart('/');
string fullPath = _basePath + relativePath.Replace(@"/", @"\");
AWSAuthConnection s3 = new AWSAuthConnection(_publicKey, _secretKey);
string sContentType = "image/jpeg";
SortedList sList = new SortedList();
sList.Add("Content-Type", sContentType);
// Set access control list to "publicly readable"
sList.Add("x-amz-acl", "public-read");
// Set to expire in ten years
sList.Add("Expires", GetHttpDateString(DateTime.Now.AddYears(10)));
S3Object obj = new S3Object(FileContentsAsString(fullPath), sList);
s3.PutObjectAsStream(bucket, relativePath, fullPath, obj.Metadata);
}
There's only two lines you need to care about if you're using S3 to host web content, and they're both commented. One sets the file to be readable by the public, and the other tells it not to expire until after you've left the company. Sorted.
I've included a cheesy .aspx page that you can use to push your files by hand. Hopefully you can figure out how to change which directories it's putting in the list, and how to add your own. It's actually pretty ugly code, but hey, it's just an admin tool that you'll only run a few times in your life.
Be Warned though: I've stripped out the security that keeps people from the outside world (and GoogleBot) from hitting this page and bogging your server. If there's any chance that this might escape to the live site, be sure to lock it down so that you can't see it unless you're logged in as an admin!
Anyway, I hope you find some use out of that code. I certainly wasn't planning to publish it, so please refrain from mentioning the 47-odd things in it that you
should never do in production!
Enjoy!
paint chat software
by
Jason Kester
Discuss on hacker news